

🎯 Abstract








💡Motivation

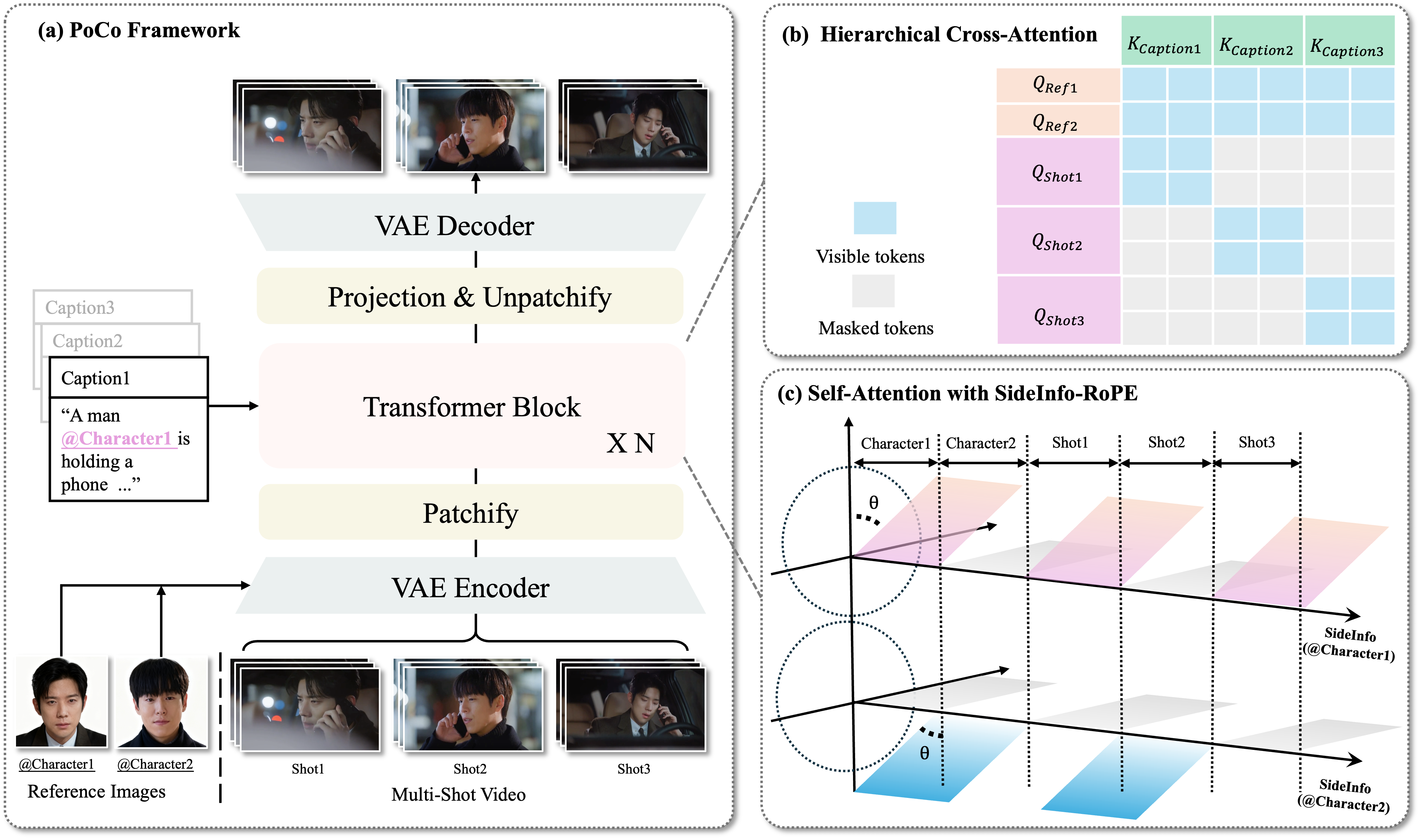
🧠 SideInfo-RoPE
✨Pipeline
🧩 Hard Cases: Identity Exchange Control
Under Semantic Overlap
Gallery
When references share highly overlapping semantic attributes, text prompts alone are often too coarse to encode fine-grained identity cues. Here we explicitly specify shot-level control: @Character1 denotes the top reference, and @Character2 denotes the bottom reference.
@Character1

@Character2

A
Shot1 → @Character1
Shot2 → @Character2
Shot3 → @Character1
B
Shot1 → @Character2
Shot2 → @Character1
Shot3 → @Character2
@Character1

@Character2

A
Shot1 → @Character1
Shot2 → @Character2
Shot3 → @Character1
B
Shot1 → @Character2
Shot2 → @Character1
Shot3 → @Character2
Ethics Concerns
The videos in these demos are generated by models, and are intended solely to showcase the capabilities of this research. If you have any concerns, please contact us at luyuningx@gmail.com, and we will promptly remove them.